








Pandas یا Python Data Analysis از ابزارهای معروف برای تحلیل و کار با داده هاست که با استفاده از ساختارهای داده و امکاناتی که در پانداس تعبیه شده (مثل دیتافریم ها)، عملیات تحلیل و پاکسازی و آمادهسازی داده را در پایتون میتوان خیلی سریع و آسان انجام داد.
برای نصب pandas، دستور زیر را اجرا میکنیم:
pip install pandas
برای شروع کار با pandas، ابتدا آن را با دستور import، وارد میکنیم:
import pandas as pd
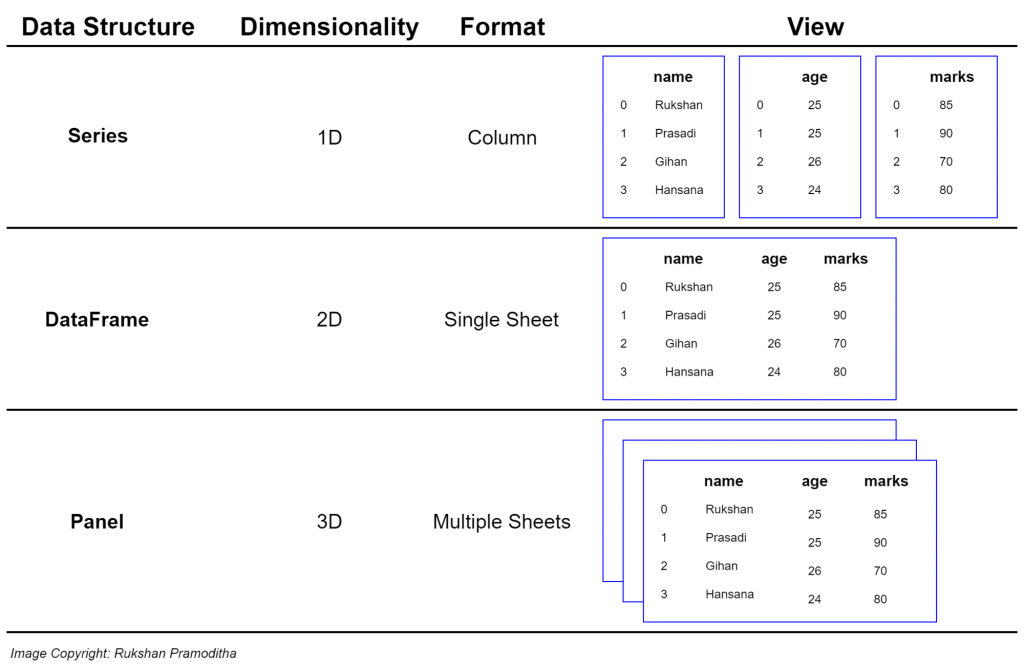
در اینجا خوب است بدانید که pandas از سه ساختمانداده پشتیبانی میکند که در ادامه مشاهده میکنید:
Series: ساختماندادهای برای نگهداری دادهها در یک بعد است که مقادیری از انواع دادهها را نگهداری میکند و بهصورت زیر قابل استفاده است:
series = pd.Series([1, 2, 3])
Dataframe:ساختماندادهای برای نگهداری دادهها در دو بعد است و از دو قسمت ردیفها و ستونها تشکیل شده است و بهصورت زیر قابل استفاده است:
df = pd.DataFrame({‘name’: [‘abolfazl’], ‘age’: [24]})
Panel:ساختماندادهای برای نگهداری دادهها در سه بعد است و از سه قسمت قسمت items و major_axis و minor_axis تشکیل شده است و بهصورت زیر قابل استفاده است:
panel = [[[0 for k in xrange(n)] for j in xrange(n)] for i in xrange(n)]
بهصورت خلاصه این ساختماندادهها بهصورت زیر هستند:
در ادامه به برخی از مهمترین توابع Pandas اشاره میکنیم:
تابع read_csv: برای خواندن فایل csv به کار میرود و بهصورت زیر قابل استفاده است:
df = pd.read_csv(FILE)
تابع to_csv: برای نوشتن ذخیره دادهها بهصورت فایل csv به کار میرود و بهصورت زیر قابل استفاده است:
df.to_csv(NAME)
تابع iloc: برای دسترسی به مقداری در ساختمانداده براساس جایگاه بهکار میرود و بهصورت زیر قابل استفاده است:
df.iloc[[0], [0]]
تابع loc: برای دسترسی به مقداری در ساختمانداده براساس کلید بهکار میرود و بهصورت زیر قابل استفاده است:
df.loc[[0], [‘name’]]