







وب معنایی (Semantic Web) توسط کنسرسیوم جهانی وب W3C ارائه و رهبری میشود. در وب مفهومی، صاحبان وبسایتها تشویق به گنجاندن محتوای معنایی در صفحات وب خودشان میشوند تا کاربردیتر و ساختار پذیرتر به اشتراک گذاشته شوند. وب مفهومی در یک تعریف ساده و قابل فهم آیندهای از وب کنونی است که تمامی بخشها در آن علاوه بر انسانها، توسط ماشینها نیز قابل فهم و پردازش است.
سوالی که ممکن است برایتان پیش بیاید این است که چرا باید ماشینها نیز بتوانند اطلاعات مورد نیاز ما را بفهمند یا پردازش کنند؟ پاسخ بسیار ساده است برای کمک بیشتر به ما انسانها. به عنوان مثال اطلاعات به نحوی ثبت شده و توسط ماشینها فراخوانی شوند تا زمانی که شما نحوه تغییر زبان ویندوز 10 را در اینترنت جستجو میکنید موتور جستجو به جای نمایش دهها هزار لینک به عنوان پاسخ، خود پاسخ را به شما نمایش دهد.
اگر چه در حال حاضر بخشی از این مسیر پیموده شده است اما هنوز با آیندهای که مورد انتظار است فاصله نسبتا زیادی دارد. برای درک بهتر وب معنایی در تصویر زیر عبارت نحوه تغییر زبان در ویندوز 10 به زبان انگلیسی مورد جستجو قرار گرفته است.
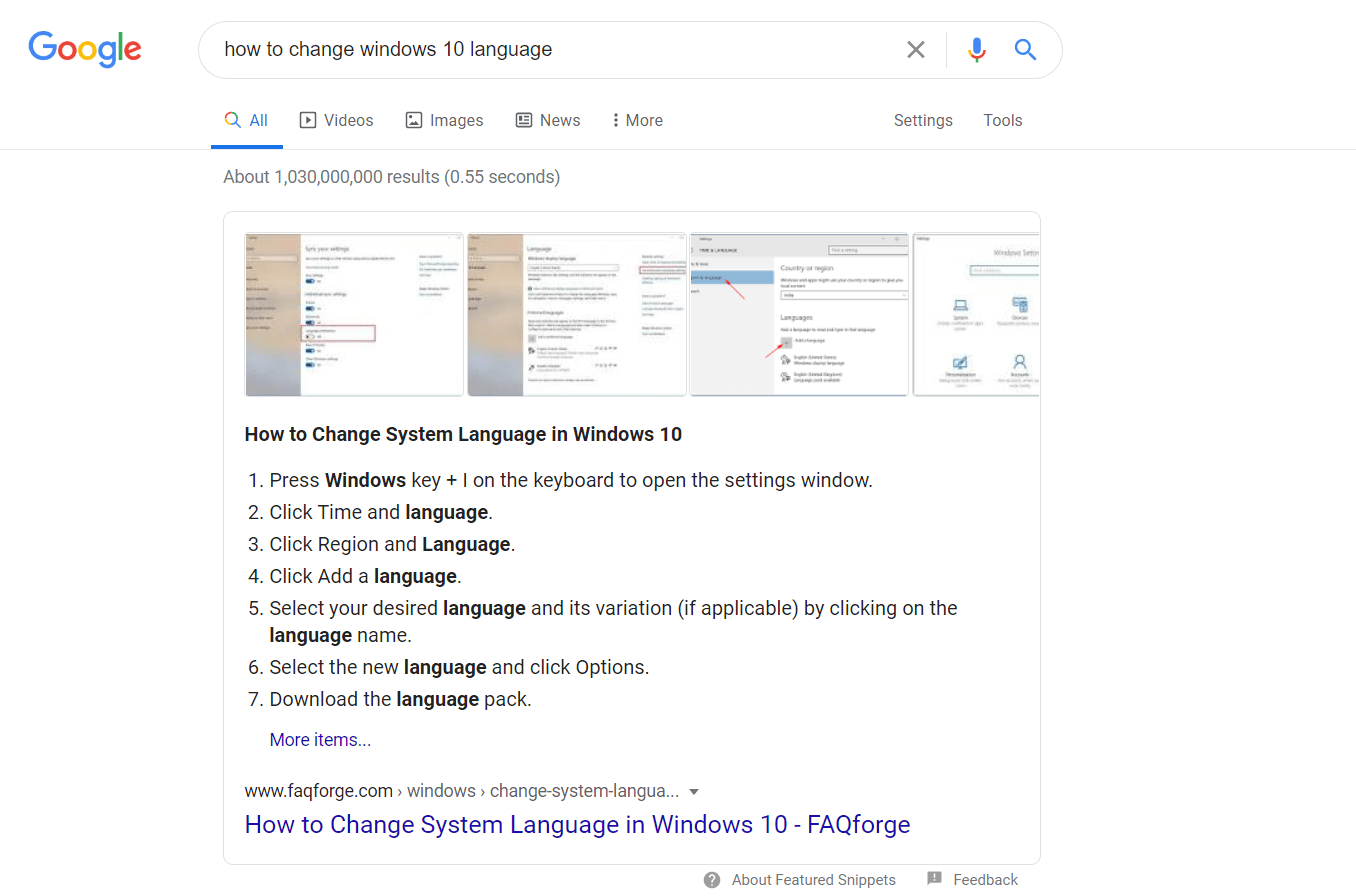
تصویر بالا بخشی از نتیجه جستجوی مورد نظر است که مقدار قابل توجهی از پاسخ را همراه با ترتیب انجام در پاسخ نمایش داده است. این یعنی به جای جستجو میان دهها لینک مختلف، برای رسیدن به پاسخ همان چیزی که دنبالش هستیم را همراه با اسکرین شاتهای آموزشی در نتیجه جستجو و در کنار سایر نتایج نمایش داده شده است. یعنی همان پاسخی که از یک متخصص کامپیوتر دریافت میکردید و این شروع یک تحول بزرگ در وب است.
البته این امکان هنوز در تمامی بخشها و زبانها پیاده سازی نشده است و اگر شما عبارت بالا را به زبان فارسی جستجو کنید پاسخ را در نتایج جستجو مشاهده نخواهید کرد.
تاریخچه وب معنایی
در حقیقت مفهوم و مدل شبکه معنایی در اوایل دهه شصت توسط دانشمندانی همچون کولینز، راسکوئلیین و الیزابت F.Loftus زبانشناسان و روانشناسان پر آوازه در نشریات مختلف به عنوان نحوهای از نمایش دانش ساخت یافته به صورت مفهومی ابداع شده بود. اما به صورت تخصصی در زمینه وب توسط تیم برنرزلی که مخترع وب گسترده جهانی نیز هست، ابداع و ارائه شد.
تیم برنرزلی، رئیس کنسرسیوم جهانی وب (W3C) بر این عقیده است که وب نیز مانند انسان پس از 20 سالگی به مرحله شکوفایی میرسد و هنوز از تواناییهای وب به درستی استفاده نشده. در حال حاضر او بر توسعه استانداردهای مورد نیاز و مطرح شده وب مفهومی نظارت دارد. البته باید به این نکته توجه داشت که در بسیاری از موارد فناوریهایی که توسط W3C مطرح شدهاند قبل از این که تحت توسعه W3C قرار بگیرند، در نوعی دیگر وجود داشتهاند.
اهمیت و نیاز کنونی به وب مفهومی
روزانه میلیونها کاربر در محیط اینترنت هزاران درخواست را راجع به اطلاعاتی خاص جستجو میکنند. از طریق اینترنت دسترسی سریع و آسان به اطلاعات مورد نظر بدون محدودیت جغرافی امکان پذیر شده است. اما این سرویسهای پرکاربرد شامل معایبی نیز هستند.
به عنوان مثال انتشار مطالب غیر واقعی، عدم مشخص شدن بهترین و درستترین پاسخ، نمایش پاسخ در ازای معرفی هزاران راه برای رسیدن به نتیجه و آرزوی استفاده از یک وب هوشمند که به نوعی مانند دستیار انسان عمل کند سبب شد تا احساس نیاز به فناوریهایی که از نظر معنایی درخواست دریافت اطلاعات را درک کرده و اطلاعات درست و مورد نظر را به سرعت در دسترس کاربران قرار داده و یا خدمات ضروری برای اجرای درخواستها را از راه دور ارائه دهند، در دستور کار افراد ذیربط قرار گیرد.
ساختار وب معنایی
ساختار وب مفهومی بر پایه درک درستی از نحوه جستجوی کاربر و اطلاعات موجود در وب بنا شده است یعنی زمانی که یک کاربر عبارتی را جستجو میکند موتور جستجو همانند یک انسان باید احساس موجود در آن جمله را متوجه شود. به عنوان مثال تشخیص دهد که این عبارت پرسشی، علمی، سرگرمی یا خبری است. سپس بر اساس آن، محتوای مناسب را که پاسخی در مقابل احساس جمله است، به کاربر نمایش دهد.
بنابراین وب معنایی مورد انتظار میبایست بر زبان شناسی و فلسفه تسلط یابد تا بتواند تمام محتویات وب که شامل صفحات، تصاویر و سایر المانهای وب است را به خوبی تحلیل و دستهبندی کند. به عنوان مثال یک ایندکس کننده موتور جستجو باید زمانی که یک متن را میخواند بتواند فاعل، مفعول و گزاره موجود در جمله را درک کرده و پیوستگی جملات در یک پاراگراف را تشخیص دهد.

بنابراین ساختار وب معنایی به این گونه است که به جای جمع آوری دادههای گسستهای که علمی به آن ندارد، اطلاعات قابل فهم را ذخیره کرده و نمایش دهد. به همین منظور نیاز بود تا زبان نمایش در وبسایتها یا همان HTML تغییر یابد و از جنبه بصری که تنها بر اساس نحوه نمایش مطالب صرفا برای درک انسان کار میکرد به سمت مفهومی شدن برای رباتها و انواع ماشینها برود. به عنوان مثال به جای استفاده از تگ b برای bold کردن مطالب مهم از تگ معنایی strong استفاده شود. تا رباتی که برای ایندکس کردن مراجعه میکند به راحتی متوجه شود که این بخش از متن اهمیت بالایی در موضوع مقاله دارد.
در واقع تا پیش از ظهور وب معنایی و HTML5 خزندهها یا همان رباتهای موتور جستجو فقط تعدادی کلیدواژه و عبارت را ایندکس میکردند و با جستجوهای کاربران آنچه جمع آوری کرده بودند بر اساس شرایطی به کاربر نمایش میدادند. اما انتظار جامعه امروزی با نمایش همین موارد کوچک به تحقق نمیپیوندد.
یکی از اهداف وب معنایی این است که مانند یک دستیار تمامعیار عمل کند و بتوان برخی از کارها را به او محول کرد. به عنوان مثال زمانی که میخواهیم به پزشک مراجعه کنیم بتواند یک وقت ویزیت را در نزدیکترین مکان و زمان با مناسبترین قیمت از یک پزشک شناخته شده در وبسایتهای مربوطه یافته و نتیجه را جهت تایید ثبت به ما بازگرداند.
در این شرایط ما تنها به ربات مربوطه میگوییم که ویزیت چه پزشکی در چه بازه زمانی مورد نظر ما است. برای رسیدن به این هدف معماری خاصی پایه ریزی شده است که دارای لایه بندی خاصی است که یک شبه محقق نمیشود. بنابراین بر اساس یک فلسفه وب معنایی دارای لایهها و بخشهای متعددی است که میتوان گفت مهمترین آنها شامل لایه XML، لایه RDF یا Resource Description Framework، لایه آنتولوژی، لایه منطق و اثبات و در نهایت لایه Trust هستند.
۱) لایه XML
بهتر است ابتدا با مفهوم XML آشنا شویم. XML مخفف Extensible Markup Language است. که در اینجا قصد داریم کمی در مورد مهمترین بخش آن یعنی Markup یا نشانه گذاری توضیح دهیم. Markup در واقع مورد استفاده در متادیتا است. متادیتاها، اطلاعاتی درباره اطلاعات و در حقیقت جدا از خود اطلاعات هستند. یعنی زمانی که میخواهیم به مرورگر بفهمانیم یک جمله تیتر و موضوع مقاله ما است آن را با استفاده از یک نشانه مشخص میکنیم.
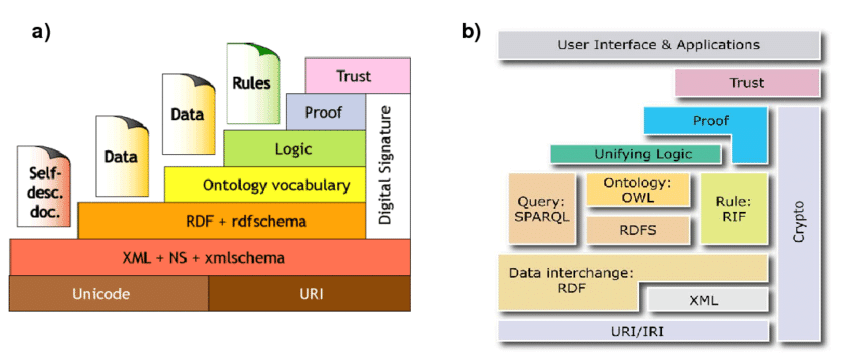
HTML نیز یکی از زبانهای کلاسیک نشانهگذاری است. به عنوان مثال زمانی که ما موضوع مقاله را با تگ H1 مشخص میکنیم در کنار این که به مرورگرها اعلام میکند که این اطلاعات را به چه صورت را نمایش دهند، به رباتهای ایندکس کننده اعلام میکند که این بخش موضوع مقاله است؛ یعنی مهمترین بخش مربوط به مقاله! همین امر سبب میشود که مطالب برای رباتهای موتور جستجو قابل فهمتر باشند.
مشکلات در ساخت وب معنایی (XML به جای HTML)
HTML زبانی است که در همه شرایط خروجی یکسانی دارد و مانند سایر زبانهای برنامهنویسی قابلیت پویایی و بازگردانی اطلاعات مختلف در شرایط گوناگون را ندارد. یعنی مرورگرها یک صفحه وب را در هر شرایطی به همان شکل اصلی طراحی شده نمایش میدهند.
برای مثال فرض کنید که یک فایل ساخته شده از HTML جهت ایمیل مارکتینگ تهیه کردهاید و میخواهید زمانی که به کاربران ارسال میشود به صورت کاملا متفاوت از دیگری برای هر کاربر نمایش داده شود. در وب معنایی ما بدنبال روش و یا روشهایی برای تفکیک بین داده و نمایش هستیم و زبان HTML به دلیل وجود محدودیتهایش گزینه مناسبی نخواهد بود.
برای رفع این مشکل XML معرفی شد که قابلیت تفکیک بین دو مقوله داده و نمایش را دارد. بر خلاف HTML تکنولوژی XML دارای اطلاعات و تگهای از قبل تعریف شده برای نحوه نمایش اطلاعات نیست و میتوان نرمافزارهایی را برای انجام عملیات دلخواه بر روی اطلاعات موجود در سند XML طراحی کرد. اما XML برای مشاهده انسان مناسب نیست به همین دلیل میتوان جهت مشاهده انسان آن را به HTML تبدیل کرده و جهت خواندن ماشین آن را دوباره به XML بازگرداند.
اما مشکل XML این است که اصطلاحاتی که در آن به کار برده میشود حالت استانداردی ندارند و هنگامی که دو ماشین از طریق آن می خواهند با یکدیگر ارتباط برقرار کنند نمیتوانند مفهوم تگهای به کار رفته در آن را بفهمند چرا که برای درک هر دو ماشین باید این ساختار را بشناسند. به همین دلیل اگر چه XML توانست برخی از مشکلات را در راه رسیدن به وب معنایی حل کند اما مشکل دیگری بر آن افزود و آن نبود زبان ساختارمند و بدون محدودیت بین ماشینها بود.
۲) لایهی RDF
همانطور که گفته شد فراداده یا متادیتا، دادههایی دربارهی خود داده هستند. به عنوان مثال قفسههای یک فروشگاه کتاب را در نظر بگیرید که از طریق کارتابلهایی به نوع محتوای کتابهای آن قفسهها اشاره دارند. آن کارتابلها همان فردادهها یا متادیتاها هستند که اطلاعاتی درباره کتابها که همان دادهها هستند در اختیار ما قرار میدهند.
RDF همانند نویسندهی این کارتابلها عمل میکند و تمام اشیای موجود در وب را که شامل متنها، تصاویر، فایلها و … هستند به عنوان منابعی در نظر میگیرد که در رابطه با آنها میشود جملاتی بیان کرد. سپس RDF با توجه به ساختار کلی این جملات شروع به ساختن فراداده برای صفات معیّنی میکند.
در واقع RDF طراحی شد تا یک روش عمومی را برای تعریف اطلاعات به گونهای ارائه دهد که به وسیلهی برنامههای کامپیوتری خوانده و فهمیده شود. توصیفات و مستندات RDF در XML نوشته میشوند. زبان XML که از RDF در آن استفاده شده RDF/XML نامیده میشود. همچنین تعریفهای RDF روی وب نمایش داده نمیشوند. RDF همه چیز را با استفاده از شناسههای وب یا همان URI یا نامک تشخیص میدهند و منابع را با خصوصیات و مقادیر خصوصیات تعریف میکند.
موارد استفاده RDF
RDF در تشریح تمامی بخشها و المانها در وب معنایی حرف اول را میزند. به عنوان مثال شرح ویژگیهایی برای اجناس تجاری، مانند قیمت و تعداد موجود، توصیف اطلاعاتی دربارهی مقالات و صفحات وب مانند موضوع، نویسنده، تاریخ ایجاد و تغییر، شرح تصاویر وب و… از جمله کارهایی هستند که توسط RDF انجام میپذیرند.
مشکلات RDF
RDF نیز مشکلاتی همچون تعدد معنا (Polysemy) را در لغتهایی که چندین معنی مختلف میدهند را دارد. و همچنین مشکل اصطلاحاتی هستند که ممکن است دارای معنایی باشند که با معنی لغوی آنها متفاوت است. مانند ضرب المثلها یا یا اصطلاحات در زبان انگلیسی که درک آنها بسیار مشکل است، مشکل سوم کلمات هم معنی هستند.
با توجه به این که موتورهای جستجو بر اساس کلمات کار میکنند میتواند موجب خطا در اطلاعات نمایش داده شده شود. همچنین موتورهای جستجو فقط نتایجی را در پاسخ نمایش میدهند که حاوی لغت مورد نظر باشد در صورتی که گاهی نمایش لغات مترادف با واژه مورد نظر نیز میتواند بسیار کاربردی باشد.
مشکل چهارم نیز عدم اطلاع از دانش مخاطبی که سوال را میپرسد است. یعنی شخصی که یک عبارت را جستجو میکند تا چه حدی به آن موضوع اشراف دارد و میخواهد چه میزان بیشتر از آن اطلاعات دریافت کند. به عنوان مثال صحبت کردن به زبان عامیانه و سریع با یک زبانآموز جدید موجب میشود که نتواند صحبت ما را متوجه شود و این صحبت عملا بیفایده خواهد بود.
میل به یافتن راه حال برای این مشکلات، ما را به سمت آشنایی با مفهومی به نام هستی شناسی یا آنتولوژی (Ontology) میبرد.
۳) لایهی آنتولوژی یا هستیشناسی
هستی شناسی، مطالعه فلسفی ماهیت هستی، وجود یا واقعیت است. این بخشی از شاخه اصلی فلسفه است که با عنوان متافیزیک شناخته میشود. هستی شناسی با سوالاتی در مورد چگونگی طبقهبندی موجودات با توجه به تشابهات و اختلافات سروکار دارد.
اما بین آنتولوژی در فلسفه و آنتولوژی در علم کامپیوتر و بالاخص آنتولوژی در وب معنایی تفاوت اساسی وجود دارد. فلسفه از طریق نظم و ترتیب میان مفاهیم به آنتولوژی میرسد، اما علم کامپیوتر دارای چنین ترتیبی نیست و آنتولوژی را از روی ترتیبی که ما برای مفاهیم در نظر میگیریم استخراج میکند. آنتولوژی در فلسفه نگاهی جامع دارد و سعی میکند تا همهی مفاهیم مورد بررسی قرار بگیرند، در حالی که آنتولوژی در علم کامپیوتر دارای دامنهی بسیار کوچکتری است و تنها مواردی که در حیطهی مورد نیاز ما هستند مورد بحث قرار میگیرند و این امر کار را تا حدود فوقالعاده زیادی تحت تاثیر قرار میدهد.
اما آنتولوژی در وب معنایی نگاهی باریک بینانهتری به مفاهیم دارد و صرفا جهت رفع و غلبه بر مشکلات موجود در RDF باید از آن بهره ببریم. به بیان سادهتر در آنتولوژی وب معنایی تلاش می کنیم به مفاهیم معادل بپردازیم. بنابراین میتوان گفت که آنتولوژی دارای جایگاهی منطقی است.
۴) لایهی منطق و اثبات
همانطور که گفته شد هدف وب معنایی کارکرد مشترک بین انسان و کامپیوتر است. بر این اساس یک انسان باید محتوایی بنویسد که ماشین آن را درک کند و ماشین نیز محتوایی را در پرسش انسان برگرداند که توسط او قابل درک باشد که این یعنی مکالمهی بین انسان و ماشین. اما امکان مکالمه میان انسان و کامپیوتر به معنی کامل شدن وب معنایی نخواهد بود.
ماشینها باید از زبانهایی برای توصیف آنتولوژی استفاده کنند که امکان تبدیل شدن به سطح مناسبی از منطق توصیفی را داشته باشند. منطق توصیفی بسیار مناسب ساختار وب معنایی است چرا که یکی از زبانهای نمایش دانش است که برای نمایش واژهای و ساختارمند دانش مورد استفاده قرار میگیرد. زبانهایی همچون OWL ,RACER, KL-ONE که مبتنی بر منطق توصیفی عمل میکنند در وب معنایی مورد استفاده قرار میگیرند.
۵) لایهی اطمینان (TRUST)
در آخرین لایه، یعنی لایهی اطمینان یا Trust کیفیت اطلاعات وب و صحت و سقم آن سنجیده میشود. در حال حاضر و در وب فعلی این امکان برای کاربران وجود ندارد و تنها از طریق برخی از امکاناتی چون SSL و بعضی نمادها و پروتکلها این اطمینان را تا حدی به دست میآورند. اما آیا این اطمینان راجع به مطالبی که در وب منتشر میشود نیز صدق میکند و یا همه افراد قابلیت استفاده از روشهای موجود را دارند؟ آیا حفظ حریم خصوصی برای همه امکانپذیر است؟
به عنوان مثال زمانی که از یک فروشنده در یکی از شبکههای اجتماعی مانند اینستاگرام خرید میکنید میتوانید به او اطمینان کنید؟ به همین دلیل مبحث اعتماد به یکی از معضلات وب فعلی تبدیل شده است. اما در دستورالعمل وب معنایی اعتمادسازی جهت برقراری تعاملات امن در اولویت قرار دارد و در صورت پیادهسازی آن، وب معنایی میتواند به صورت بسیار مطلوب عمل نماید.
شما چه نظری در خصوص وب معنایی دارید؟ به نظر شما این فناوری تا چه حد در زندگی ما تاثیرگذار خواهد بود؟
شما یک گام جلوتر از دیگران باشید! اگر به آیتی و تکنولوژی علاقهمندید و دوست دارید سریعتر در این زمینه پیشرفت کنید، همین حالا به جمع 6238 عضو همیار آیتی بپیوندید، دسترسی به تمام آموزشهای پریمیوم، دریافت جدیدترین آموزشهای کاربردی مرتبط با آیتی و استفاده از مشاورهی رایگان، برخی از مزایای عضویت در سایت هستند، شما نیز به کاربران همیار پیوسته و همین حالا وارد دنیای حرفهایها شوید…
منبع:https://www.hamyarit.com/internet/semantic-web/