






تعریف و مفهوم متن کاوی
به فرایند پیدا کردن قوانین و الگوهای غیربدیهی، جدید (از قبل نامشخص)، مخفی، احتمالاً مفید و کاربردی از انبوه دادههای (پیکره) مستندات را متن کاوی (Text Mining) یا تحلیل متن (Text Analytics) میگویند. در تعریف دیگر، متن کاوی به فرایند تحلیل و اکتشاف انبوهی از متون غیرساختیافته بوسیله نرمافزار به منظور شناسایی مفاهیم، الگوها، موضوعات، کلیدواژهها و دیگر ویژگیهای دادههای متنی گفته میشود. به عبارت دیگر هدف متن کاوی، کشف معنا (مفهموم و هدف) و استخراج اطلاعات نهفته (برای مثال موجودیتها و روابط) در دادههای متنی است.
فرایند متن کاوی
متن کاوی نوعی داده کاوی بر روی دادههای متنی است. ولی هدف، تکنیکها و فرآیند آن کمی متفاوت از داده کاوی است. برای مثال ممکن است هدف از متن کاوی، خلاصهسازی مستندات، تشخیص موضوع متن، شناسایی حس نویسنده و … باشد. در شکل زیر فرآیند و روال متداول متن کاوی نشان داده شده است.

در اغلب زمینههای متن کاوی نیاز به پیشپردازش متن با استفاده از ابزارهای پردازش زبان طبیعی و سپس تبدیل دادههای متنی به بردارهای عددی داریم. منظور از ابزارهای پردازش متن، کتابخانههایی است که برای آمادهسازی متن جهت متن کاوی و استخراج دانش از متن بکار میروند. انشاءالله بزودی در مقالهای جداگانه درباره انواع مدلهای زبانی و رویکردهای تبدیل متن به بردارهای عددی بطور مفصل صحبت خواهیم کرد. در گام بعد با توجه به هدف و صورت مساله، فرایند اصلی متن کاوی (داده کاوی برای دادههای متنی) انجام میشود. در نهایت، نتایج خروجی متن کاوی بعد از ارزیابی نیاز به بصریسازی (Visualization) برای نمایش به شخص خبره (مدیران) دارد. همچنین با بازنمایی دانش (Knowledge Representation) با استفاده از تکنیکهای وب معنایی (Semantic Web) از قبیل تهیه هستانشناسی (Ontology)، قابلیت استنتاج و تهیه گزارشات مختلف امکانپذیر خواهد بود.
پیشنهاد میکنیم برای آشنایی بیشتر با حوزه متن کاوی، مطالب تهیه شده در خصوص مفاهیم پردازش زبان طبیعی، کاربردهای متن کاوی و ابزارهای پردازش متن را مطالعه بفرمایید.
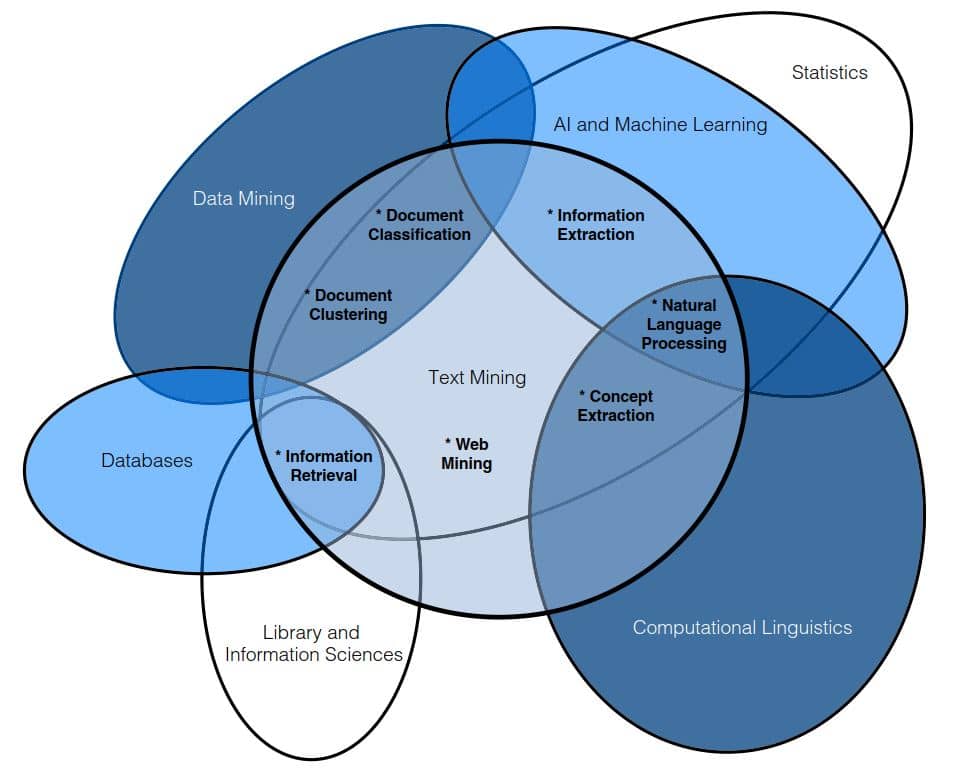
مسائل و زمینههای اصلی متن کاوی
همانطور که در شکل بالای این نوشته مشاهده میکنید، حوزه متن کاوی (دایره پررنگ وسط) شامل ۷ زمینه و مساله اصلی است:
- دستهبندی متون (Document Classification): فرایند انتخاب بهترین برچسب (موضوع یا نمایه، نوع حس، …) برای متون بدون برچسب (untagged documents) از مجموعه برچسبهای از قبل مشخص شده، با استفاده از مدلی که از روی متون برچسبگذاری شده (دادههای آموزشی) یادگرفته و ساخته شده است. به عبارت دیگر ابتدا از روی مجموعه مستندات دارای برچسب (که داده آموزشی نام دارند) یک مدل محاسباتی (پیشگو) ساخته میشود که به این مرحله، یادگیری مدل یا آموزش میگویند. به دلیل وجود داده آموزشی و برچسبدار به دستهبندی یک روش باناظر (Supervised) میگویند. در مرحله بعد، با استفاده از بخش مجزایی از مستندات دارای برچسب (که در ابتدا از دادههای آموزشی جدا کردیم) مدل ساخته شده را تست میکنیم تا میزان دقت آن برای پیشبینی برچسب مستندات مجموعه تستی ما مشخص شود. به این مرحله، آزمایش یا تست میگویند. اگر کیفیت مدل ساخته شده مطلوب نباشد، باید به مرحله اول برگشته و پارامترهای الگوریتم دستهبندی یا روش ساخت مدل را تغییر دهیم و در غیراینصورت به مرحله بعد میرویم. در نهایت در مرحله آخر با استفاده از مدل از ساخته شده، به پیشبینی و تشخیص برچسب سایر مستندات بدون برچسب میپردازیم که به این مرحله، بکارگیری میگویند.
- خوشهبندی متون (Document Clustering): به فرایند گروهبندی مستندات مشابه درون خوشههای مختلف خوشهبندی میگویند. به دلیل عدم استفاده از دادههای برچسبدار به خوشهبندی یک روش بدون ناظر یا بدون نظارت (Unsupervised) گفته میشود. پس دو عامل 1- فرمول و نحوه محاسبه شباهت/فاصله دادههای متنی و 2- رویکرد و نحوه گروهبندی (نوع الگوریتم و پارامترهای آن) در نتایج خوشهبندی موثر هستند.
- بازیابی اطلاعات (Information Retrieval-IR): فرایند شاخصگذاری (indexing)، جستجو (searching) و بازیابی و استخراج (retrieving) مستندات از بین مجموعه دادههای عظیم متنی با توجه به کلیدواژههای پرسوجو (query) را بازیابی اطلاعات میگویند. مهمترین کاربرد بازیابی اطلاعات در موتورهای جستجوی وب از قبیل گوگل، بینگ، یاهو و … دیده میشود.
- وب کاوی (Web Mining): فرایند داده و متن کاوی روی محتوای صفحات و ارتباطات (لینکهای) بین صفحات وب را وب کاوی میگویند. صفحات وب حالتی نیمهساختیافته از متون و لینک (ارتباط) به صفحات دیگر تشکیل شدهاند. لذا یک رویکرد متداول برای وبکاوی، بازنمایی صفحات وب در قالب گراف و تحلیل گراف وب هست. امروزه زیرشاخهای از وبکاوی برای تحلیل شبکههای اجتماعی مانند فیسبوک، توئیتر و … بسیار مورد توجه پژوهشگران و کسبوکارهای مختلف قرار گرفته است.
- استخراج اطلاعات (Information Extraction-IE): فرایند شناسایی و استخراج موجودیتهای مناسب و همچنین روابط بین آنها از درون متن (غیرساختیافته) را استخراج اطلاعات میگویند. به عبارت دیگر استخراج اطلاعات فرایندی برای پردازش دادههای غیرساختیافته (مثل متن، تصویر، صوت، …) یا نیمهساختیافته (مثل صفحات وب، XML، …) و ساخت (تبدیل کردن آنها به) مجموعه داده ساختیافته (از قبیل جداول پایگاهداده) است. استخراج اطلاعات به دو نوع باز (عمومی) و بسته (خاص و در حوزه مشخص) تقسیم میشود. فیلد استخراج اطلاعات یکی از زمینههای مهم و بسیار دشوار متن کاوی است.
- پردازش زبان طبیعی (Natural Language Processing-NLP): هدف آن، پردازش سطح پایین و فهم (درک) زبان و بخصوص متن توسط کامپیوترها است. معمولاً معادل با اصلاح زبانشناسی محاسباتی (computational linguistics) بکار گرفته میشود، هرچند که اغلب زبانشناسان زبانشناسی محاسباتی را کلیتر از پردازش زبان طبیعی میدانند.
- استخراج مفاهیم (Concept Extraction): فرایند گروهبندی کلمات و عباراتهای متن درون گروههای مشابه معنایی را استخراج مفاهیم میگویند. معمولاً از تکنیکهای آماری (مانند n-grams یا همرخدادی)، تعبیه کلمات (word embedding)، مدلسازی موضوعات (topics modeling) و خوشهبندی متون و کلمات برای استخراج مفاهیم استفاده میشود.
ارتباط بین زمینههای مختلف متن کاوی
در شکل زیر یک طبقهبندی جالب از مسائل و زمینههای مختلف متن کاوی در قالب یک درخت تصمیم انجام شده است.

در شکل زیر نیز علاوه بر نمایش اشتراک و رابطه بین زمینههای مختلف متن کاوی، فیلدها و مسائل مهم مربوط به هر زمینه نشان داده شده است.

کاربردهای متن کاوی در دنیای واقعی
قبلاً در مقاله دیگری درباره مسائل کاربردی متن کاوی از قبیل خلاصهسازی خودکار، نمایهزنی (تشخیص موضوع) متن، تحلیل احساسات، چتباتها، مترجمهای ماشینی، موتورهای جستجو و … صحبت کردیم. اکنون قصد معرفی کاربردهای ابزارها و تکنیکهای متن کاوی در حوزههای مختلف زندگی بشر را داریم :
- تجارت و کسبوکارها : کاربردهایی از قبیل تحلیل حس و میزان رضایتمندی مشتریان نسبت به محصولات یا شرکتها، گرایش و علاقه بازار نسبت به ویژگیهای مختلف محصولات، شناسایی سلیقه یا رویدادهای زندگی کاربر و تبلیغات موثر، شناسایی خودکار و فیلتر نظرات نامناسب (غیرقابل انتشار) کاربران و …
- اقتصادی : تحلیل اخبار و پیشبینی شاخصهای مختلف اقتصادی، تحلیل و شناسایی رابطه بین رویدادهای مختلف با شاخصهای اقتصادی، تحلیل بازار بورس و …
- سیاسی : تحلیل شبکههای اجتماعی برای شناسایی حس و میزان رضایتمندی مردم نسبت به کاندیداهای انتخاباتی و موضوعات مختلف جامعه، شناسایی موضوعات داغ (Trend) و تحلیل شکلگیری، گسترش و جهتدهی آنها، شناسایی شایعات و اخبار جعلی (Fake News) در فضای مجازی و …
- کتابخانهای : نمایهزنی و دستهبندی موضوعی مقالات و کتابها، مشابهتیابی بین مستندات مختلف، جستجوی (غیردقیق) متن یا عبارت در بین حجم انبوه منابع و …
- جامعهشناسی و روانشناسی : تحلیل علائق، خصوصیات و خلقیات افراد، شناسایی و تحلیل لحن و نحوه بیان نشریات و رسانههای مختلف برای القای مقصود خود به افراد و …
- حقوقی و جرمشناسی : تشخیص سرقت ادبی، تشخیص نویسنده متن (با توجه به سبک نگارش)، شناسایی انواع پیامها یا نظرات مشکوک، تبلیغاتی، دارای عبارات توهینآمیز و …
- آموزش : ویرایش و اصلاح متون، کمک به انسان برای یادگیری زبانهای جدید، …
- زیستشناسی : نام این فیلد به متن کاوی دادههای زیستی (Biomedical Text Mining) معروف است که بیشتر روی تحلیل تعاملات بین توالی پروتئین آنها و ارتباط و وابستگی بین آنها با بیماریها با استفاده از تکنیکهای متن کاوی تمرکز دارد.
- روزمره : مترجمها، موتورهای جستجو، دستیارهای صوتی و متنی، چتباتها و سیستمهای پرسش و پاسخ و …
بعضی تصاویر و مطالب برگرفته از کتاب Practical Text Mining and Statistical Analysis for Non-structured Text Data Applications هستند.
استفاده از مطالب این مقاله با ذکر منبع “سامانه متن کاوی فارسییار – text-mining.ir“، بلامانع است.