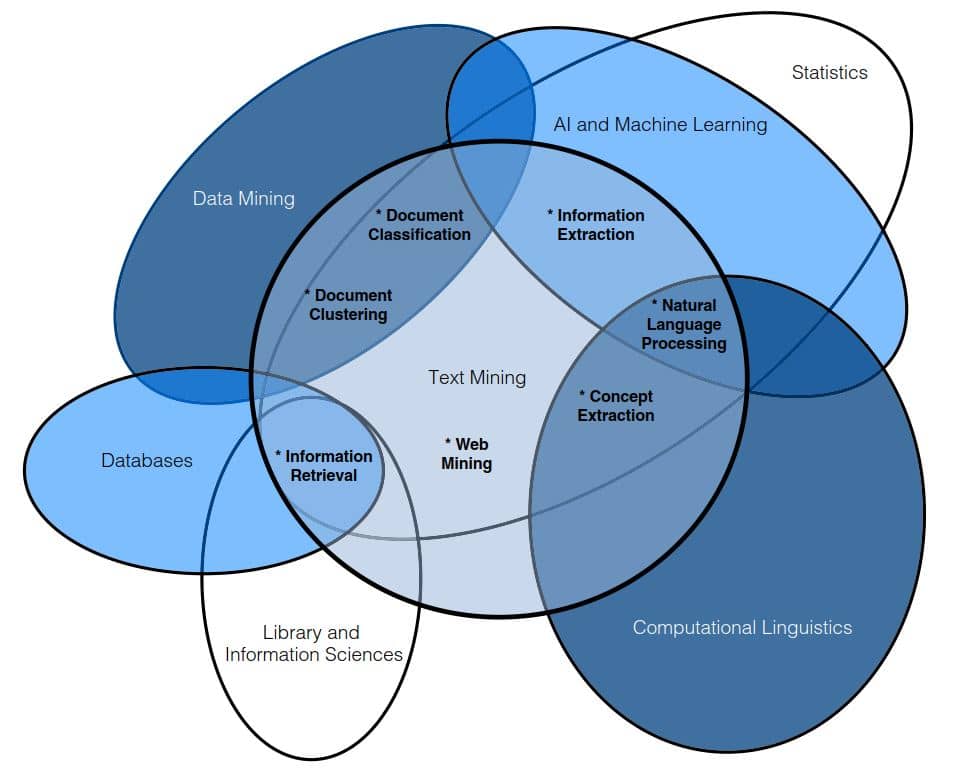
چکیده : رشد سریع اسناد منتشر شده در وب ، درخواست های جدیدی برای پردازش ، طبقه بندی و بازیابی اطلاعات ایجاد کرده است. بنابراین ، استفاده از ابزارهای پردازش زبان طبیعی در سراسر جهان افزایش یافته است. خلاصه سازی خودکار به عنوان هسته طیف گسترده ای از ابزارهای پردازش متن مانند سیستم های تصمیم […]

پردازش متن - وب معنایی

تحلیل شبکه های اجتماعی

هوش مصنوعی در سلامت

شهر هوشمند

داده کاوی